Design 3 analysis
The third design involves using a relational database to autoincrement an id, then the app can encode it into a short url. Generally, using RDBMS for the first phase of the application lifecycle works pretty well as it is very easy to implement.
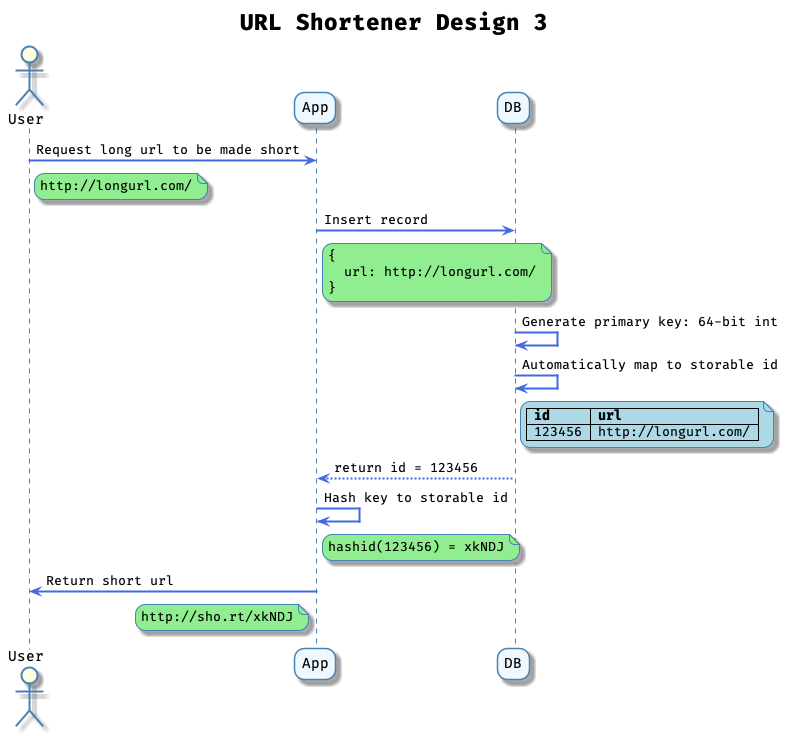
Application design to physical limits
We already know the application limits. The address space works fine as we need 44 bits and we can have 64 bit indexes.
From the initial requirements, we need to have a total of 50 TB of storage and support a total IOPS of 4000 or 40000 at peak.
An EBS volume (gp2) can be up to 16 TB with 10000 IOPS per volume. And naively, we can put 23 EBS volumes on a single machine. The total storage for 10 years is approximately 60 TB. Having 5 volumes would work. This can be managed as a logical unit on a single machine. From RDS Aurora benchmarks, a machine can do 100000 writes and 500000 reads with an r3.8xlarge with 32 cores and 244 GB memory, so the CPU should also be fine at the database layer. FInally, the network would be at peak $40000 * 500\text{ bytes} = 4 * 10^4 * 500 = 2000 * 10^4 = 20 * 10^6 = 20\text{ MB/s}$. Most systems have gigabit connections, so even with multiple slaves, the network should not be an issue.
The app should only take a few ms and then we are hopefully in an epoll loop at the database. The entire request cycle should be around 10 ms. The main question now is how much context-switching will affect the overall throughput. Naively, we can say each core can handle $\dfrac{1}{10\text{ ms/request}} = 100\text{ requests/sec}$. This would mean on average we need 40 coes and at peak 400 cores. However, we know it should be much less because of the epoll loop. The application side encode/decode/http-request handling/db query should be on the order of ms. Benchmark yourself to confirm.
This should cover the calculations for the CPU, memory, network and disk for both the app and database. Regarding fault tolerance, we need to have a standard master-slave setup. Automated failover ranges from 30s to 90s.
For initial requirements, this is the simplest design from a development and maintenance perspective.